Under RMB10K! 4 GPUs! 64GB VRAM! Hand-Built Water-Cooled 4-Card V100 Server Tutorial
Author: Second-Rate Programmer
Published: June 14, 2025, 16:05
Location: Beijing
Preface
I recently hand-built a server with 4 GPUs, 64GB VRAM, capable of running 70B DeepSeek models with output performance reaching 25 tokens/s - incredibly smooth. It's truly hand-built - I scraped my fingernails and separated nail from flesh, and it still hurts several days later! So I can't let this effort go to waste - I'm sharing this tutorial with everyone.
 Completed 4-card V100 server assembly
Completed 4-card V100 server assembly
Hardware Configuration List
| Component | Model/Specification | Description |
|---|---|---|
| Motherboard | 7048GR (Supermicro) | Taiwanese manufacturer Supermicro motherboard, also used by high-end cards like H100, H200 |
| Graphics Cards | Tesla V100 × 4 | 16GB HBM2 VRAM each, totaling 64GB VRAM |
| Power Supply | 2000W | Multi-GPU machines require high-wattage PSU |
| Cooling | 480 radiator water cooling system | External mounting |
| Adapter Cards | SXM2 to PCIe × 4 | V100-specific adapter cards |
Note: The motherboard is 7048GR, from Taiwanese manufacturer Supermicro. High-end graphics cards like H100 and H200 also use motherboards from this company. Second-hand servers bought online might be branded as Inspur or Sugon, but the motherboards are all the same, and the cases are similar too.
Why Choose V100?
Performance Characteristics
The V100 was once the computational king of data centers. IBM used these GPUs to build the Summit supercomputer, which was once the world's #1 supercomputer. Now retired from data centers and available to consumers, but performance remains strong:
- Computing Power: Equivalent to RTX 2080Ti
- VRAM Capacity: 16GB HBM2 high-bandwidth memory per card
- Overall Performance: 4 V100s have computing power equivalent to RTX 4090, but far exceed 4090 in VRAM
Performance Comparison
 GeekBench OpenCL test: One 4090 roughly equals two V100s
GeekBench OpenCL test: One 4090 roughly equals two V100s
Performance comparison between V100 and 4090 in different application scenarios:
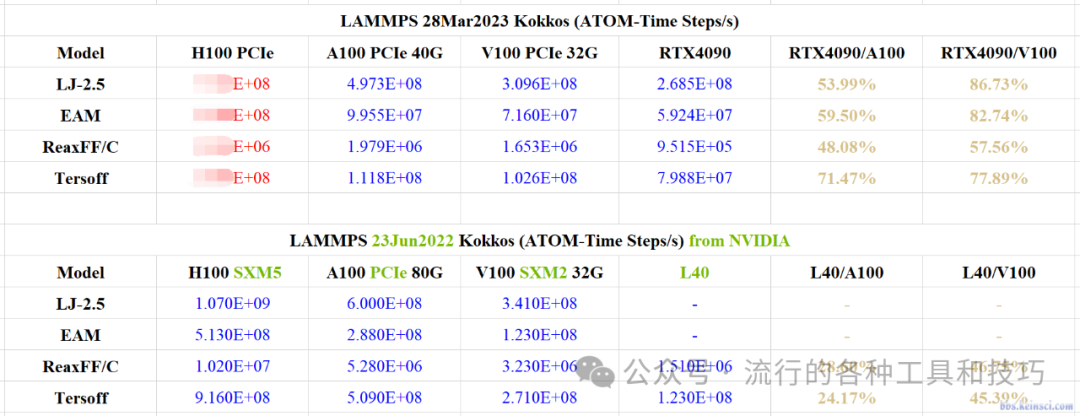 In computational chemistry applications, 4090 performs worse than V100 in some computing packages
In computational chemistry applications, 4090 performs worse than V100 in some computing packages
Cost-Performance Advantage
The V100 is absolutely the cost-performance king in the current GPU market. However, using this GPU well is not easy because:
- Interface Issues: The GPU was designed for data centers with SXM2 interface, requiring adapter cards
- Cooling Requirements: High power consumption (max 300W per card), demanding excellent cooling
- Installation Complexity: Requires manual modification and precise installation
Cooling Solution Selection
Power Consumption Calculation
- Maximum power per V100 GPU: 300W
- Total power consumption for 4 cards: 1200W
- Cooling requirements: Estimated 240 radiator can handle two cards, 4 cards need 480 radiator
Actual Installation
After arrival, found the 480 radiator was indeed too large to fit inside the server, had to install externally.
 External 480 radiator cooling system
External 480 radiator cooling system
Detailed Installation Process
Adapter Card Installation
 SXM2 to PCIe adapter card in original state
SXM2 to PCIe adapter card in original state
Each V100 GPU requires installation of: - SXM2 to PCIe adapter card - Custom water cooling block
 V100 with adapter card and water cooling block installed
V100 with adapter card and water cooling block installed
Case Installation
 Final installation of four V100s inside the case
Final installation of four V100s inside the case
The four cards installed side by side still have some clearance, and water cooling takes up relatively little space. However, when installing the water tubes, it really requires manual precision work, making the installation process quite difficult.
Temperature Testing
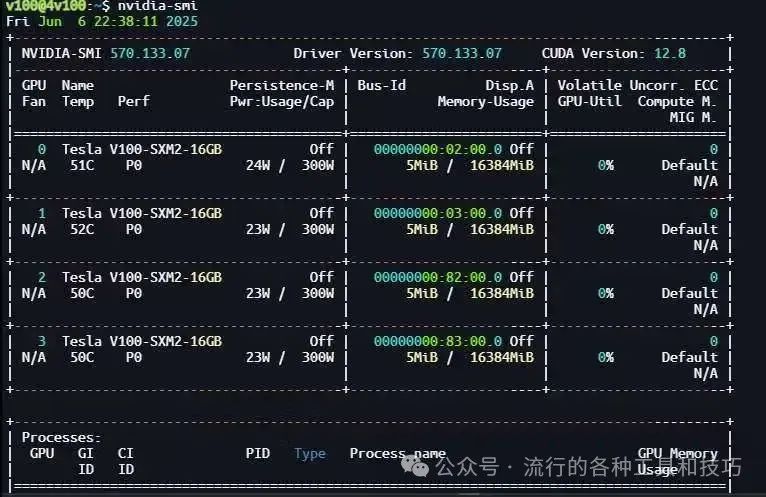 Temperature monitoring when water cooling not fully installed, around 50+ degrees
Temperature monitoring when water cooling not fully installed, around 50+ degrees
Temperature performance after installation completion: - Idle State: Close to room temperature - High Load Operation: Under 60 degrees at 200+ watts per card
Performance Testing
DeepSeek 32b Model Testing
Successfully running 32b DeepSeek model with excellent fluidity in actual operation:
 Click to watch: 4-card V100 running DeepSeek demonstration video
Click to watch: 4-card V100 running DeepSeek demonstration video
Performance Metrics: - Model: DeepSeek 70b - Output Speed: 25 tokens/s - Running State: Very smooth
Summary
This hand-built 4-card V100 server has the following advantages:
Hardware Advantages
- High Cost-Performance: Under $10K cost
- Large VRAM: 64GB HBM2 VRAM, suitable for large model inference
- Stable Performance: Data center-grade hardware reliability
Applicable Scenarios
- Individual AI developers
- Small and medium enterprise AI applications
- Research institutes and project teams
- Local deployment of large models
Technical Features
- Supports 70B parameter large models
- Inference speed reaches 25 tokens/s
- Excellent temperature control, stable long-term operation
Future Plans
If everyone needs more detailed installation tutorials, I can introduce them module by module: - Hardware selection and procurement guide - Detailed installation steps - System configuration and software environment setup - Performance tuning and troubleshooting
If you also want such a high cost-performance AI server, welcome to contact the author for more technical support and custom services!
This tutorial demonstrates how to build a professional-grade AI computing server with extremely high cost-performance. Although the installation process requires certain hands-on ability, the final performance and cost advantages are worthwhile. For AI application scenarios requiring large VRAM and high computing power, V100 remains an excellent choice.
Contact Author
